
A new AI technology known as VersAI, a proprietary AI technology from Verseon, is challenging the dominance of deep learning—especially in areas where data is scarce. In a recent preprint, Verseon researchers and a colleague at the Missouri University of Science and Technology show that VersAI can train predictive models considerably faster than Google AutoML, based on benchmark test results. In well-known classification benchmarks—such as human activity recognition (HAR), chemical toxicity prediction (QSAR), and text-based CNAE-9—VersAI routinely trained up to thousands of times faster than multilayer neural nets while boosting accuracy on underrepresented classes, as well as overall accuracy.
Machine learning techniques have always required choosing hyperparameters. While hyperparameters are often selected manually, automated methods have grown more common under the umbrella of Automated Machine Learning (AutoML). Google AutoML is a pioneer in this area with its Google AutoML offering. Yet, as the arXiv paper describes, VersAI is considerably more efficient at a number of tasks thanks to its use of Extreme Learning Machines (ELMs), which significantly reduce both the complexity of hyperparameter tuning and the overall training time. Head-to-head benchmarking described in the “Extreme AutoML” paper shows VersAI not only surpasses Google AutoML in speed but also offers superior accuracy when data is sparse or underrepresented.
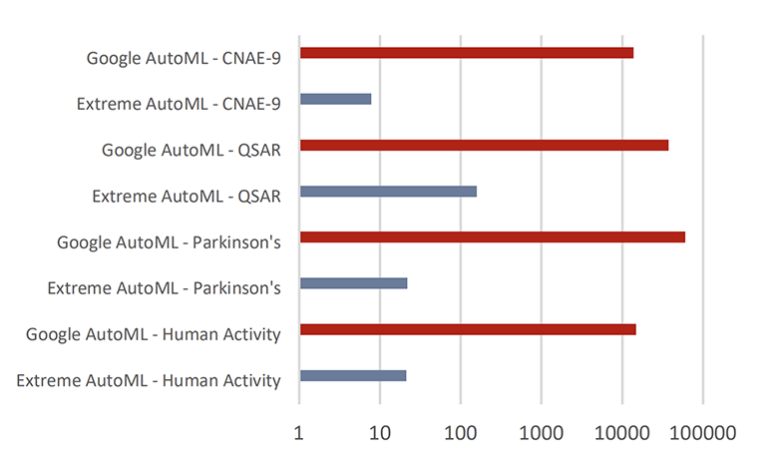
The benchmarking studies were based on well-known datasets from the University of California, Irvine (UCI) repository, in which VersAI not only delivered dramatic speedups but also excelled at handling sparse data.
“When we started brainstorming, the main question was: What if we focus on that sparse-data problem?” recalled Edward Ratner, Ph.D., Verseon’s head of machine learning. “Deep learning evolved under the big data paradigm. But if your data is relatively sparse… you need another approach.” The number of sample points is context dependent. “For some problems, a million sample points is sparse; for others, 10,000 is dense. It’s problem-dependent,” Ratner said. “But what we had seen was that when data was sparse, deep learning often didn’t do very well—sometimes older machine learning methods performed better, or were at least comparable.”
Tacking the sparse data problem with a new approach
Most modern AI frameworks rely on deep neural networks trained via iterative backpropagation—an approach that has fueled many breakthroughs but also requires enormous amounts of labeled data, specialized hardware, and painstaking hyperparameter tuning. Because VersAI doesn’t do iterative optimization, “we don’t need derivatives,” Ratner said. Back propagation, based on the chain rule in calculus, is used for iterative optimization. “We don’t do iterative optimization, so we don’t need to compute derivatives,” Ratner said. “So, we can use these nonlinear elements like medians.”
“If you can’t rely on traditional deep learning techniques, and you want to use powerful tools like medians, how do you actually design a practical system?” he asked.
Answering that question, Ratner explained, required a shift in perspective—from focusing solely on the algorithm to also considering the nature of the data itself. Ratner points to a different challenge: datasets that are “small and wide.” Such datasets are typical in many real-world scenarios such as drug discovery and specialized industrial applications. “When we started brainstorming, the main question was: What if we focus on that sparse-data problem? Deep learning evolved under the big data paradigm. But if your data is relatively sparse… you need another approach,” he said.
That “other approach” turned out to be an ensemble of “Extreme Learning Machines” (ELMs), known collectively as “Extreme Networks.” ELMs compute their hidden-layer weights in a single linear step, eliminating the iterative backpropagation used by deep networks. The architecture also dispenses with manual hyperparameter tuning, making it faster and more tractable for users who may not have massive datasets or who can’t afford days or weeks of GPU time.
Extreme networks, dynamically generated collections of shallow random networks, are considerable different from deep learning in some respects, but they still have a neural network of threshold-activation neurons plus other numerical nonlinear elements. “Deep learning can’t do that because it needs all elements to be differentiable, and something like a median (which we use in our networks) isn’t differentiable,” Ratner said.
Head-to-head benchmarks
In the paper, the authors compared VersAI’s Extreme AutoML to Google AutoML on multiple classification datasets (including the Human Activity Recognition and CNAE-9 corpora), a regression dataset predicting the revenue of American movies, and an NLP task with SMS spam detection. Although Google AutoML provides various modeling approaches, VersAI’s ELM-based approach consistently trained in a fraction of the time—often hundreds or thousands of times faster—while delivering superior or comparable accuracy. “Within deep learning, there are many different architectures. So, for a meaningful comparison, we decided to benchmark against Google’s AutoML framework, which dynamically chooses an optimal deep-learning network architecture,” Ratner said.
In particular, the researchers also evaluated performance using metrics beyond raw accuracy. For instance, they measured the Jaccard Index—a metric that reflects how well a model performs on each individual class within a dataset. For an example of a class, consider the CIFAR-10 dataset, which contains 60,000 images divided into 10 classes. One of those classes is “automobile”; the other classes include items like “airplane,” “truck,“ “cat,” “dog,” “horse,“ etc. In reality, some classes are much less common than others.
“The paper highlights that VersAI not only achieved higher average Jaccard Indices but also showed significantly lower variance across classes,” Ratner said. “This means the model performed consistently well even on underrepresented groups, avoiding the common pitfall of deep learning models that prioritize overall accuracy at the expense of minority classes.”
This advantage is important in drug discovery, where the ability to accurately predict properties of rare or novel compounds can make or break a research program.
VersAI’s approach also extends to text processing. The paper describes how its auto-generated ELM ensembles matched the performance of large language models on an SMS spam classification task.
“Models that produce higher Jaccard Indices for underrepresented classes and thus much lower Jaccard index variability illustrate greater generalization and utility.” “Extreme AutoML produced a lower variance of Jaccard Indices across classes for each of the datasets when compared to Google AutoML in each case when the class variance was significant.” and, most directly addressing class imbalance:
“We benchmarked our approach on that SMS dataset against a number of alternatives. We beat all of them and matched OpenAI’s result to four decimal places—even though OpenAI’s model was trained on around 100 times more data than RoBERTa,” Ratner said.
Potential in drug discovery and beyond
One hurdle when using deep learning in drug discovery is the potential to deal with “small, wide datasets,” as Ratner calls them. For instance, when generating new molecules or screening large compound libraries, this can be common, creating a challenge for standard deep learning systems.
This limitation leads many deep models to fail at extrapolating beyond training data—especially when used naively for generative tasks in drug design. Ratner also points out that numerous industries face similar challenges with underrepresented classes or constantly changing data distributions. As a result, Verseon has positioned VersAI as a general-purpose AI that can bring benefits to e-commerce, finance, retail, and more.
The difference in training speed has significant cost and environmental implications. Verseon’s press release notes that “in scenarios that take Deep Learning technologies months to generate models, VersAI takes mere minutes.” These speed gains also translate to a much smaller hardware footprint, as the ELM-based ensembles do not require the specialized GPUs or large CPU clusters typical of deep networks. Whether in pharma, movie-revenue prediction, or text classification, Extreme AutoML suggests a break from the “bigger is better” formula that has dominated machine learning for the last decade.
ABOUT THE AUTHOR

Brian Buntz
As the pharma and biotech editor at WTWH Media, Brian has almost two decades of experience in B2B media, with a focus on healthcare and technology. While he has long maintained a keen interest in AI, more recently Brian has made making data analysis a central focus, and is exploring tools ranging from NLP and clustering to predictive analytics.
Throughout his 18-year tenure, Brian has covered an array of life science topics, including clinical trials, medical devices, and drug discovery and development. Prior to WTWH, he held the title of content director at Informa, where he focused on topics such as connected devices, cybersecurity, AI and Industry 4.0. A dedicated decade at UBM saw Brian providing in-depth coverage of the medical device sector. Engage with Brian on LinkedIn or drop him an email at bbuntz@wtwhmedia.com.